

Architecture Diagram
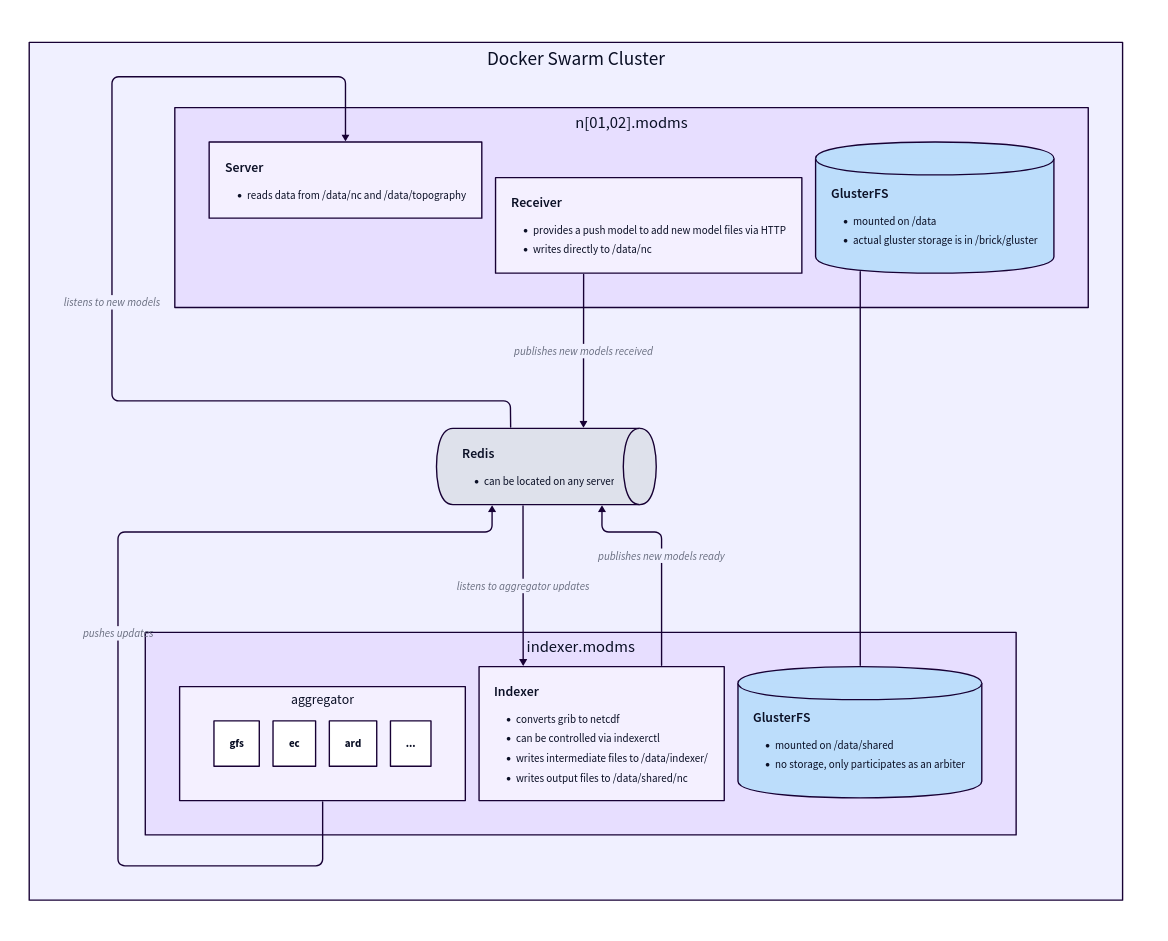
Components
- Aggregator
- Indexer
- Server
- Receiver
The data ingestion component responsible for downloading and preprocessing model data.Responsibilities:
- Downloads models according to schedule
- Performs model-specific post-processing on GRIB files
- Notifies the indexer when new files are ready
- Must be on the same server as the indexer to share the filesystem
Data Flow
Storage Architecture
ModMS uses GlusterFS for distributed storage, providing:Servers & environments
- Core ModMS nodes
- File storage
Typical ModMS deployment uses:
n01.modms.devops.arabiaweather.comn02.modms.devops.arabiaweather.comindexer.modms.devops.arabiaweather.com(Indexer server)
/data and host the Aggregator, Indexer, and Server components.GlusterFS Architecture Details
ModMS uses a replicated GlusterFS volume with:- Multiple brick nodes for data storage
- Arbiter node for split-brain prevention
- Self-healing daemon for automatic recovery
- TCP transport for network communication
Performance Considerations
Server Startup Time
Server Startup Time
The server scans all NetCDF files at startup, which can take approximately 3 minutes with large datasets.
For cold starts, it’s recommended to start with 2 container replicas and scale up once ready.
File System Requirements
File System Requirements
The Aggregator and Indexer must share a filesystem, requiring them to run on the same server.
Storage Optimization
Storage Optimization
NetCDF format is used for efficient querying and reduced storage overhead compared to raw GRIB files.